Primeiros passos no Linux

Introdução
Atualmente, os computadores estão em todos os lugares, desde os menores relógios até gigantescos data centers, onde tudo está conectado. E, com a onipresença desses dispositivos, foi inaugurada uma nova era de empoderamento e liberdade criativa sem precedentens. Apesar disso, um punhado de grandes corporações detêm o controle sobre a maioria dos computadores do mundo e decidem dia após dia o que podemos ou não fazer com eles.
Felizmente, desenvolvedores no mundo inteiro trabalham em conjunto para desenvolver uma série de ferramentas que permitem expressar nossa liberdade e criatividade sem depender de coisas que não entedemos ou não podemos ver. O Linux, como projeto de software, é um dos mais ricos ecossistemas que nasceram desse esforço coletivo e é constantemente mantido para continuar cumprindo tal propósito.
Dessa forma, para nos tornamos grandes desenvolvedores e garantir a nossa autonomia, é crucial entender essa ferramenta e a comunidade que a cerca.
O que é o Linux?
Portanto, podemos começar entendendo o que de fato é o Linux.
Muitas vezes, nos confundimos ao pensar que Linux é um sistema operacional assim como o Windows ou Mac OS, mas não é bem isso. Linux, na verdade, é o que chamamos de kernel, isto é, no sentido literal, uma parte do sistema que controla os recursos do computador, permite que os usuários rodem programas, controlem os periféricos conectados e, também, um sistema de arquivos que gerencia o armazenamento a longo prazo de informação, como programas, dados e documentos.
Num sentido um pouco mais amplo, quando falamos “Linux”, nos referimos a um combo chamado “GNU/Linux”, onde “GNU” (GNU is Not Unix; mais sobre o UNIX depois) é uma camada superficial sistema que corresponde um pacote de programas, como compiladores, editores de texto e os programas que usamos diariamente.
Num sentido ainda mais amplo, quando falamos “GNU/Linux” ou apenas “Linux”, falamos de uma família de sistemas os quais implementaram o que o Linux e GNU e os tornaram utilizáveis. Cada membro da familia é o que chamamos de distro Linux (mais sobre isso no futuro), que agora, de fato, é um sistema operacional completo.
Portanto, podemos enxergar o Linux como um descendente de consideração de uma família chamada Unix, e chamamos essa descêndencia de Unix-Like.
Família Unix e Unix-Like
A coisa interessante sobre o Unix é que sua filosofia de desenvolvimento de software e implementação foi tão revolucionária que inspirou e inspira até hoje diversos paradigmas de programação, ao ponto de o chamarmos de o pai de todos os sistemas operacionais. Mas por que ele foi e é tão importante?
Primeiro, porque foi o primeiro sistema escrito em C, ou seja, ele podia facilmente ser portado para qualquer arquitetura. Segundo, também por ser escrito em C, o código do sistema é muito acessível e fácil de manter e melhorar. Por último e mais importante, porque ele é muito bom, principalmente para programadores.
Apesar de ter sido, inicialmente, um projeto de pesquisa privada da Bell Labs, o sucesso foi tanto que desenvolvedores do mundo inteiro queriam desenvolver sua própria alternativa “livre do Unix”. Essa iniciativa deu origem aos sistemas BSD (Berkely Software Distribution), GNU/Linux e até o Mac OS (esse, não tão livre assim :P). Como as BSDs e Linux sofrem muitas variações, as chamamos de Distros, que são distribuições/implementações diferentes do pacote inicial.
Distros
Linux
Como foi dito anteriormente, Linux é apenas uma família de sistemas, e cada sistema é chamado de distro Linux. Existem uma série de diferenças entre essas distros, que dependem da implementação de quem os gerencia. Além disso, pelo GNU e o Linux serem “software livre” qualquer uso e implementação do Kernel Linux e do projeto GNU tem que ser gratuita e código aberto. Mas então, qual é a principal diferença entre essas distribuições?
Arch

Uma das mais minimalistas e customisáveis, o Arch tem como propósito a simplicidade ao extremo no seu pacote básico. Desde a instalação até a configuração de cada detalhe, a responsabilidade é do usuário, ou seja, cada acerto e cada erro é exclusivamente seu. Devido as essas características, o Arch é muito popular entre usuários mais entusiastas e programadores.
Debian

Conhecido pela sua estabilidade e segurança, o Debian é muito popular em servidores, ambientes corporativos e entre usuários que buscam lidar com a menor quantidade de problemas possíveis. Para isso, o Debian tem um ciclo de lançamento mais lento, o que significa que as atualizações são menos frequentes, mas mais testadas.
Em contrapartida, o ciclo de lançamento do Arch é infinitamente mais rápido, o que significa que as atualizações são mais frequentes, mas menos testadas.
Ubuntu

Sem dúvida, uma das distros mais populares, o Ubuntu é conhecido pela sua facilidade de uso e instalação, de tal forma que é muito popular entre usuários que estão começando a usar Linux, pois abstrai muitas nuances que podem ser intimidadoras para novos usuários.
Além disso, o Ubuntu é baseado no Debian, o que significa que ele herda muitas características positivas, como, em parte, a estabilidade e segurança.
Mint

Nascido do Ubuntu, o Mint tem a proposta de ser ainda mais amigável e fácil de usar que o Ubuntu. Isso o torna, também, uma alternativa muito viável a usuários que estão começando a usar o Linux e não se preocupam muito com customização e minimalismo.
BSD’s
Ao lado das distribuições Linux, existem os sistemas operacionais BSD, que são outra família de sistemas Unix-like. BSD, que significa Berkeley Software Distribution, refere-se a uma série de distribuições de software que foram originalmente desenvolvidas e distribuídas pela Universidade da Califórnia em Berkeley. Assim como o Linux, os sistemas BSD têm um núcleo e ferramentas de usuário, mas são desenvolvidos e licenciados de maneira diferente. Exemplos notáveis de sistemas BSD incluem FreeBSD, NetBSD e OpenBSD.
Os sistemas BSD e as distribuições Linux compartilham muitas das filosofias básicas de sistemas Unix-like, mas cada família tem suas próprias comunidades, filosofias de desenvolvimento, e escolhas técnicas que os diferenciam significativamente.
Uso básico do Shell
Intro
Para entender um pouco melhor do que se trata o shell, note que na época em que o Unix se popularizou (final da década de 1970 e início da de 1980) não existia uma interface gráfica (GUI) e toda interação era feita via comandos com a ajuda de um terminal. Um terminal, por sua vez, é um programa com interface de texto que perimite interagir com o sistema operacional a partir de comandos.

- Imagem de um DEC VT100 rodando Unix (1978), fonte: https://en.wikipedia.org/wiki/VT100
Essa linha de comando e interface de texto na época era única e exclusiva responsabilidade do Shell, que é, ao mesmo tempo, uma interface de texto, uma linguagem de programação e um ambiente de execução de programas.
Atualmente, com o advento das interfaces gráficas, o Shell perdeu muito do seu papel de protagonista e hoje pode ser invocado a partir de o que chamamos de emulador de terminal. Entretanto, caso você opte por não instalar e configurar uma interface gráfica (ao instalar o Arch, por exemplo), o Shell será seu único companheiro.

- Imagem do emulador gnome-terminal rodando no ubuntu 24.04 LTS, fonte: https://canaltech.com.br/linux/ubuntu-2404-lts-e-liberado-veja-as-principais-novidades-286919/
A maioria das distros Linux vêm com o shell do projeto GNU, Bourne Again Shell (Bash) pré instalado. Não é um padrão e se você quiser, existem diversos outros que você pode instalar e usar.
Quando o shell é iniciado, o usuário se depara com uma tela do seguinte tipo:
[user@hostname ~]$
Na qual:
[user@hostname ~]$
^ ^ ^ ^
│ │ │ └─ O cifrão diz que você não é o usuário `root` (mais sobre isso depois)
│ │ └── Seu «Working Directory», o diretório que o shell está operando no momento
│ └── Nome do computador, também conhecido como o nome do host
└── Nome do usuário que está usando o shell nessa sessão
A maneira mais simples de usar o shell é digitando comandos!
Primeiros passos
Comando date e echo
Vamos começar experimentando alguns comandos básicos. Digite os seguintes comandos no seu terminal:
date que mostra a data e a hora atuais.
[user@hostname ~]$ date
e cal, que mostra o calendário do mês atual.
[user@hostname ~]$ cal
Provavelmente, você deve ter visto a data e o horário atual, assim como um calendário do mês, respectivamente. Agora, vamos testar um comando com argumento:
[user@hostname ~]$ echo Hello
^
└─ Argumentos passado para o programa (input)
Seu terminal provalvemente ficou assim:
[user@hostname ~]$ echo Hello
Hello
O programa echo apenas imprime o argumento que você passou para ele em uma stream (falaremos mais sobre isso no futuro).
O resultado que foi exibido é o que chamamos de output.
Você também pode usar o echo das seguintes formas, teste-as e veja o resultado:
[user@hostname ~]$ echo "Hello World"
[user@hostname ~]$ echo Hello\ World
Contudo, nem tudo funciona do jeito que queremos. Por exemplo, tente digitar qualquer coisa no terminal e veja o que acontece.
[user@hostname ~]$ ablueblauebluebalbbeu
Já que esse comando não faz sentido, o shell vai nos dizer que deu errado e nos dará outra chance:
bash: ablueblauebluebalbbeu: command not found
[user@hostname ~]$
Histórico de comandos
Se você pressionar ↑, o nosso comando ablueblauebluebalbbeu vai reaparecer para podermos usa-lo novamente. Se você continuar pressionando ↑, note que diversos comandos utilizados vão ser reexibidos. Isso é chamado de ‘histórico de comandos’ e a maioria das distribuições Linux armazenam por padrão pelo menos os últimos 1000 comandos. Se você pressionar ↓, você avança para o presente no histórico até o comando desaparecer.
Navegando com o Shell
Assim como no Windows, um Unix-Like organiza seus arquivos no que é chamado de Estrutura de Dirétorios Hierárquica. Isso significa que é possível visualizar esse sistema como uma árvore de diretórios, também chamados de pastas. Esses diretórios funcionam exatamente como pastas de escritório que você pode ter em casa, em que cada uma pode ter outra pasta e/ou um arquivo, e cada arquivo tem um nome, junto com informações extras como a quem ele pertence ou o quão grande ele é.
A principal diferença filosófica entre o sistema de arquivos fundado pelo Unix é que, ao contrário do Windows, que tem um arvóre de arquivos diferente para cada dispositivo de armazenamento, um Unix-like tem apenas uma árvore, que independe da quantidade de dispositivos de armazenamento conectados ao computador.
Além disso, vale ressaltar que o sistema de arquivos não é capaz de diferenciar entre formatos diferentes de arquivo (.pdf, .rar, .qualquercoisa), ele não impõe nenhuma estrutura a ser seguida por esses arquivos, o significado dos bytes que ali estão sendo armazenados dependem única e exclusivamente dos programas que lidam e interpretam com esse arquivo. Isso não é apenas verdade para arquivos genéricos, mas também para caracteres digitados no seu teclado, dispositivos conectados e tudo que você pode imaginar.
Existem sim casos especiais de arquivo, como diretórios e links simbólicos (mais sobre isso no futuro), mas eles não correspondem diretamente ao formato do arquivo, mas sim ao seu tipo.

Current working directory
Como já dito anteriormente, o sistema de arquivos funciona como uma árvore: você possui um diretório de origem, o /
(chamado de root, ou “raíz”, em Português) que seria o tronco, enquanto os galhos são os outros diretórios do computador.
A partir de um diretório,
é possível ver os diretórios diretamente ligados a ele, seja “descendo” ou “subindo” a árvore. Quando você acessa um
diretório e passa a ter acesso a todos os arquivos dentro dele, aquele passa a ser seu Working Directory. Na prática, imagine que seu sistema de arquivos é a seguinte árvore de cabeça para baixo.
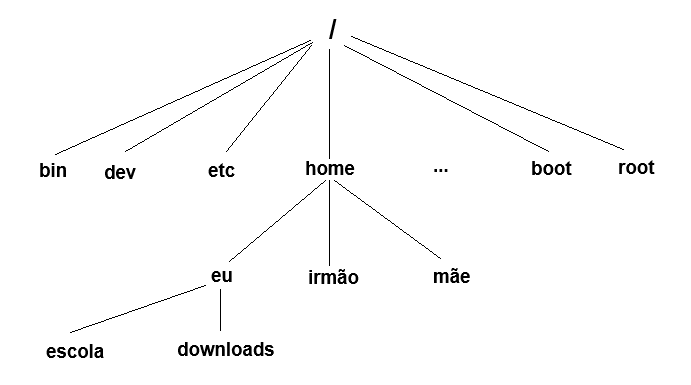
Utilizando o comando pwd (“Path to Working Directory”, ou “Caminho do Diretório de Trabalho” em Português)
é possível saber o caminho de todos os diretórios da root até o seu diretório atual:
[eu@hostname ~]$ pwd
/home/eu
Além do ‘working directory’, nós temos também o ‘home directory’, o único lugar em que usuários comuns são autorizados a escrever em um arquivo. Cada usuário possui um home directory, ou seja, por padrão, você apenas é capaz de ver outros diretórios além do seu. Se quiser editar algo que não é seu, você precisará de algo que chamamos de permissões de superusuário, ou sudo (mais sobre isso no futuro).
Caminhos absolutos e caminhos relativos
Ao navegar pelo sistema utilizando o shell, geralmente utilizamos caminhos absolutos como o do exemplo anterior. Estando no diretório /home/eu, você pode utilizar o comando cd (que significa Change Directory) para acessar o diretório /home, da seguinte forma:
[eu@hostname ~]$ cd /home
[eu@hostname home]$
(Perceba o
~mudando)
Porém, digamos que você está na pasta /downloads e deseja ir até a pasta /escola. Para isso, é necessário utilizar
o diretório especial ..
Os dois pontos representam o diretório pai de forma relativa, e podem ser utilizados para voltar enquanto se navega pelo sistema de arquivos:
[eu@hostname downloads]$ cd ..
[eu@hostname ~]$ cd escola
[eu@hostname escola]$
Também temos o diretório especial . que representa o diretório atual. Na parte de navegação de arquivos, esse caminho não é tão interessante, mas é crucial quando estamos tratando de executar comandos.
Listando, criando diretórios e arquivos
Podemos manipular diretórios e arquivos a partir de comandos:
Usando o comando mkdir (de “Make Directory”, ou “Fazer Diretório”, em Portguês), é possível criar uma nova pasta. A sintaxe do comando é: mkdir <nome_da_pasta>. Digamos que você acabou de criar na pasta escola a pasta minicurso_linux_git:
[user@hostname escola]$ mkdir minicurso_linux_git
[user@hostname escola]$ cd minicurso_linux_git
[user@hostname minicurso_linux_git]$
Vamos adicionar também um arquivo de texto para anotações da aula, usando o comando touch
(Divine touch):
[user@hostname minicurso_linux_git]$ touch anotacoes.txt
Assim que chegou em casa, após a primeira aula do minicurso, você criou essa pasta. Dentro dela, colocou um arquivo de texto com as anotações da aula e uma selfie que tirou com um colega no dia da aula.
Algum tempo se passou, você se formou na faculdade e encontrou este diretório novamente. Agora você se pergunta: “Qual é o conteúdo dele?”
Com o comando ls (List), é possível listar todo o conteúdo de um diretório:
[user@hostname minicurso_linux_git]$ ls
anotacoes.txt foto-do-quadro.jpg
Porém, você está trocando de computador e o computador no qual essa pasta foi criada não será mais utilizado. Ainda muito saudoso pelo seu tempo de novato nesse mundo do Linux, você decide levar o conteúdo dessa pasta para o seu novo computador. Usando o comando cp (de “CoPy”), você copia os arquivos para um pen-drive.
[user@hostname minicurso_linux_git]$ cd ..
[user@hostname ~]$ cp minicurso_linux_git pen-drive
e então decide removê-la, utilizando o comando rm (“ReMove”), você deleta cada arquivo:
[user@hostname ~]$ cd minicurso_linux_git
[user@hostname minicurso_linux_git]$ rm anotacoes.txt foto-do-quadro.jpg
[user@hostname minicurso_linux_git]$ ls
E agora, não resta mais nenhum arquivo na pasta e você pode finalmente removê-la com o comando rmdir (“ReMove DIRectory”).
[user@hostname minicurso_linux_git]$ cd ..
[user@hostname ~]$ rmdir minicurso_linux_git
E… pronto! A pasta agora não existe mais no computador, e você está pronto para iniciar um novo ciclo.
Opções e argumentos de comando
Filosofia Unix: Programas simples e combináveis
No Linux, e mais geralmente, no próprio Unix, cada programa e comando segue a filosofia de cumprir um único propósito e cumprir bem esse propósito. Assim, cabe ao próprio usuário combinar esses comandos para realizar a tarefa que ele deseja. Por exemplo, não faria sentido um comando específico para mandar um email, que ao mesmo tempo encomenda um tênis no varejo. É muito mais prático, e faz muito mais sentido, existir um programa que envia emails e um que encomenda coisas na internet, visto que diversos usuários vão usar o sistema de maneiras diferentes.
Mas também seria interessante que seu programa mudasse ligeiramente seu comportamento padrão para se moldar a uma necessidade que não foge necessáriamente do próposito principal do comando. Pois, talvez, você só quissese mandar um email para uma pessoa diferente ou para múltiplas pessoas. Seu próposito inicial (mandar um email) não mudou, mas o comportamento do programa sim. Nesse sentido, é conveniente mudar ligeiramente o que o nosso comando faz, por isso, urge a necessidade de opções de comando.
Excerto dessa filosofia
- Todo programa deve fazer UMA coisa bem.
- Esperar que a saída desse programa seja a entrada de outro, mesmo que esse seja desconhecido.
Opções de comando
No tópico anterior, executamos uma sequência indiscriminada de comandos para realizar uma tarefa relativamente simples.
Mas, mesmo assim, executamos diversos passos apenas para remover todos os arquivos de uma pasta para depois removê-la por
completo. Então, talvez seja conveniente para você usar o rm (remove) para remover tudo logo de uma vez sem mais nem menos. E ele, de fato, tem uma opção que faz isso, e você pode invocar essa opção da seguinte maneira:
[user@hostname ~]$ rm --recursive minicurso_linux_git
^
└ Todos (99.8%) dos comandos do unix começam com um '-' antes da opção
Assim, seu programa já vai deletar a pasta por inteiro, independente de ter arquivos dentro ou não. Além disso, existe uma certa
tendência de nós programadores querermos gastar pouca tinta em tudo que escrevemos, então muitas das opções que usamos tem uma abreviação, nesse caso, a abreviação é -r.
Opções de comando do ls
Aqui está uma versão reescrita da sua frase:
As opções variam de comando para comando, então vamos explorar algumas das opções disponíveis para, provavelmente, o comando mais customizável que temos: o ls.
Teste o comando ls com a opção -F (abreviação para --classify), que especifica o tipo de cada arquivo listado:
[user@hostname ~]$ ls -F
escola/ downloads/ Minecraft* 'Pequeno Príncipe.pdf'
A opção -F decora o ls com esses símbolos para que possamos saber que tipo de
arquivo estamos vendo, isto é, o / é para diretórios, * é para arquivos
executáveis e o @ são links para outros arquivos (ou atalhos, mais sobre
isso no futuro).
Parênteses sobre dotfiles
Outra opção que usamos muito em conjunto com o ls é a opção -a/--all,
que lista os arquivos “ocultos” do seu computador, conhecidos mais comumente
como dotfiles. Eles são chamados assim por começarem com um . no início do nome. Para descobrir o que são dotfiles tente, por exemplo, rodar o comando ls primeiro sem e depois com a opção -a/--all no seu home directory.
[user@hostname ~]$ ls ~
[user@hostname ~]$ ls -a ~
Provavelmente, milhões de arquivos e diretórios devem ter aparecido, e muitos deles começam com ., incluindo os diretórios especiais . e … Se quiser ver mais detalhadamente as diferenças, experimente o comando diff com as seguintes opções:
diff --color=auto <(ls) <(ls -a)
Como investigar comandos
Já exploramos e aprendemos um belo punhado de comandos e opções, e, conforme formos aprendendo mais, será impraticável lembrar de todos. Por isso,
o Linux vem com ferramentas que podem ser utilizadas quando se quer saber mais sobre um comando, sem ter que depender da internet ou magos da computação toda hora.
Logo, podemos consultar o comportamento e a documentação de um comando usando o man (MANual). Até para comandos mais simples, há uma quantidade absurda de informação, mas não se desespere, vamos dar uma olhada em cada parte do manual:
LS(1) User Commands LS(1)
NAME Essa seção mostra o nome do comando e diz brevemente o que ele faz
ls - list directory contents
SYNOPSIS Essa seção mostra como se usa o comando
ls [OPTION]... [FILE]...
Os colchetes nos dizem que determinado argumento é opcional, e os pontinhos dizem que
podem ser diversos argumentos. Nesse caso, ele está dizendo que pode receber várias
opções e arquivos
DESCRIPTION Essa seção mostra uma descrição detalhada do programa e quais são as opções dele
List information about the FILEs (the current directory by default).
Sort entries alphabetically if none of -cftuvSUX nor --sort is specified.
Mandatory arguments to long options are mandatory for short options too.
-a, --all
do not ignore entries starting with .
-A, --almost-all
do not list implied . and ..
...
-F, --classify[=WHEN]
append indicator (one of */=>@|) to entries WHEN
...
O manual de um comando tem tudo que é necessário para se entender como ele funciona e pode ser utilizado. Portanto, é muito importante se familiarizar com sua interface e sempre recorrer a ele quando estivermos querendo aprender algo novo, apesar de as vezes ser difícil de entender… (a galera que escreveu não é lá muito pedagógica :P).
Permissões, leitura e busca em/de arquivos
Long listing format e permissões
Continuando nossa exploração, uma opção muito utilizada com o comando ls é o -l
(Long listing format, ou “Formato de Listagem Longa”, em Português), que lista uma série de informações
extra sobre o conteúdo de um diretório. Vejamos um exemplo:
[user@hostname ~]
total 28
drwxr-xr-x 7 user user 4096 Jun 28 07:32 escola
drwxr-xr-x 5 user user 4096 Jun 28 09:33 downloads
-rwxr-xr-x 1 user user 4096 May 15 19:35 Minecraft
-rwxr-xr-x 1 user user 69 Jun 10 19:23 'Pequeno Príncipe.epub'
Onde, por exemplo:
drwxr-xr-x 5 user user 4096 Jun 28 09:33 downloads
Corresponde a:
| Campo | Significado |
|---|---|
| downloads | nome do arquivo |
| Jun 28 09:33 | Última modificação |
| 4096 | O tamanho do arquivo em bytes |
| user | O grupo de usuário ao qual o arquivo pertence |
| user | O dono do arquivo |
| 5 | O número de hardlinks (mais sobre isso no futuro) |
| drwxr-xr-x | As permissões de acesso do arquivo e o tipo do arquivo |
- As permissões de acesso e o tipo de arquivo em detalhes:
- O tipo do arquivo: d (directory).
- As permissões do usuário atual: rwx.
- As permissões do grupo de usuário: r-x.
- As permissões de outros usuários: r-x.
O Linux possui um sistema de permissões separadas por três categorias: permissão de escrita (w), permissão de leitura (r) e permissão de execução (x).
Dependendo do seu tipo de usuário, você pode ter mais ou menos permissões. No caso do ls -l, temos os três tipos:
- Autor do arquivo, Grupo do arquivo e outros.
Intuitivamente, quem costuma ter mais permissões sobre um arquivo é o seu autor, e quem costuma ter menos permissões são os outros usuários. Vamos dizer, por exemplo, que exista um grupo de programadores trabalhando em um projeto, sendo um desses programadores o autor.
O autor será responsável por testar a aplicação principal do projeto, portanto, ele terá as permissões w, r e x (escrita, leitura e execução).
Os programadores precisam se preocupar apenas com o desenvolvimento do projeto, portanto, terão as permissões w e r (escrita e leitura).
Já o usuário genérico pode apenas ver projeto, pois ele ainda não está terminado, assim, ele possui a permissão r (leitura), apenas.
Agora que entendemos a ideia geral das permissões no Linux, vamos a um conceito que será muito utilizado em toda sua trajetória nesse sistema: o super usuário.
O conceito de super usuário, ou “root”, no Linux, é muito semelhante ao conceito de “administrador” no Windows. Utilizamos do super usuário para realizar mudanças no sistema como instalar arquivos, mudar permissões, etc. Entretanto, o usuário root deve ser usado pontualmente, pois o uso indevido pode danificar o sistema de diversas formas, justamente por não ter permissões para pará-lo (com grandes poderes, vêm grandes responsabilidades). Você pode utilizar um comando como super usuário utilizando o prefixo sudo (que significa Super User Do), porém, é necessário saber a senha do computador.
Lendo arquivos
Lendo o conteúdo de arquivos de texto
Até o momento, aprendemos diversas ferramentas relacionadas a manipulação de arquivos: sabemos criar, deletar, copiar, deletar e até mesmo modificar o comportamento dos comandos. Logo, é dada hora de lermos os nossos arquivos.
E, para cumprir tal objetivo, existem muitas opções pré-instaladas que tem seu próprio uso. Vamos explorar algumas:
(Sinta-se convidado(a) a pular a explicação de cada um e já olhar direto no manual ;))
- Comando
cat(conCATenate):
O comando cat lê um ou mais arquivos e copia o conteúdo deles para o output (saída) padrão.
cat [OPTION]... [FILE]...
Note que, se você tentar em um arquivo muito grande, você não será capaz de ler tudo sem deslocar o texto manualmente usando o mouse.
- Comando
lessemore(Less is More):
O less foi desenvolvido para ser uma substituição do antigo programa do Unix chamado more. Ambos fazem
a mesma coisa, e eles caem na categoria que chamamos de pagers, que são programas que permitem uma melhor
visualização de longos documentos de texto, em contrapartida ao cat que não lhe mostra muito.
less [options] file ...
- Comando
headandtail:
Às vezes, não queremos toda informação de um arquivo. Assim, o head e o tail servem exatamente para esse
próposito. Por padrão, eles exibem as primeiras 10 e 10 últimas linhas de um arquivo, respectivamente.
head [OPTION]... [FILE]...
tail [OPTION]... [FILE]...
A quantidade de linhas exibidas pode ser ajustada com a opção -n/-lines=[-].
Links simbólicos e links físicos
Links simbólicos (sym-links)
Enquanto exploramos o sistema, é bem provável que nos deparemos com a seguinte listagem de diretório (por exemplo, ls -l /lib):
lrwxrwxrwx 1 root root 7 Apr 7 15:02 /lib -> usr/lib
Note como a primeira letra da listagem é ‘l’ e o arquivo parece ter dois nomes. Isso é um caso especial do que chamamos de ‘link simbólico’. No Windows, é equivalente ao que chamamos de ‘atalho’ e funciona exatamente do mesmo jeito. A utilidade disso agora parece ser dúbia, mas você não imagina o quanto pode ser útil, principalmente no que diz respeito a instalação de programas (mais sobre isso no futuro).
Você pode criar um sym-link para seu arquivo favorito da seguinte forma
ln -s <alvo> <link>
Se você apagar o link que você criou, o alvo persistirá intacto, mas se você apagar o arquivo original, o seu link vai ficar inutilizado.
Links físicos (hard-links)
Os hard-links eram uma alternativa mais antiga que surgiu primeiros Unix, e eles tem uma série de restrições comparadas ao sym-links. Dentre as quais:
- Os hard-links são indistinguíves do arquivo original, isto é, se você apagar um você apaga o outro.
- Um hard-link não pode referenciar um diretório.
As boas práticas de hoje em dia, tendêm a preferir o uso de sym-links, então fique atento(a)! Você pode criar um hard-link da seguinte maneira:
ln <alvo> <link>
Comandos de Busca
find - Imprime arquivos cujo correspondem a um padrão
Agora que você já sabe navegar no seu sistema com cd, ls, pwd e etc, quero lhe convidar a aprender
a usar mais um comando que pode ser muito útil na sua navegação e em diversas outras aplicações.
Imagine que você esqueceu onde estava seu diretório com todas as suas atividades deste minicurso, mas,
ao menos você lembra que o nome desse diretório começava com “minicurso_linux_git”, o comando find é uma
solução para esse e outros tipos de problema e você pode usá-lo da seguinte forma:
find [starting-point...] [expression]
# Procura todos os diretórios nomeados minicurso_linux_git
find . -name minicurso_linux_git -type d
Note que a expressão que você está procurando é opcional, então se você usar apenas find ele vai listar
loucamente todos os arquivos de todas as pastas a partir do seu diretório atual (teste!).
grep - Imprime linhas que correspondem a um padrão
Encontrar arquivos pelo nome pode ser muito útil, mas imagine que, além de estar procurando o arquivo, você
está procurando por alguma linha específica nele. Por exemplo, há um arquivo de código gigantesco de
10 mil linhas e você precisa achar quando uma váriavél foi declarada. Você pode usar o grep da seguinte forma:
grep [OPTION...] PATTERNS [FILE...]
Algumas opções úteis do grep são:
-i, diz para ogrepignorar a diferença entre letras maiúsculas e minúsculas.-v, diz para ogrepimprimir apenas aquelas linhas que não correspondem ao padrão.
Redirecionando e combinando comandos
Standard Input, Output e Error
A maioria dos programas que usamos até agora produzem uma saída (output) de algum tipo. E essa saída geralmente consiste em dois tipos:
- O resultado do programa, o que era esperado ele fazer.
- Mensagens de error, ou mensagens descritivas sobre algo que ele fez ou está fazendo.
Relembrando um dos mantras do Unix em que “tudo é arquivo”, programas como o ls na verdade mandam seus
resultados para um tipo especial de arquivo chamado standard output (também conhecido como stdout)
e sua mensagem de error para outro tipo especial de arquivo chamado standard error (stderr). Por
padrão tanto ou stdout quanto o stderr são associados a janela do seu programa e não são salvos no seu disco.
Além disso, a maioria dos programas recebem entrada de outro tipo especial de arquivo chamado standard input (stdin), que é associado ao arquivo seu teclado.
Redirecionando o Standard Output e Standard Error
Lembra do que eu falei sobre a filosofia do unix?.
Naturalmente, podemos mudar um pouco o comportamento do standard output e error e mandá-los para
outro arquivo sem ser o seu terminal, para fazer isso, basta usar o operador > seguido pelo nome do
arquivo. Por exemplo:
- Para redirecionar a stdout:
ls -l /usr/bin > ls-output.txt
Note que, se o ls emitir erros, eles continuão sendo impressos na tela, tente:
ls -l /bin/usr > ls-output.txt
- Para redirecionar a stderr:
ls -l /usr/bin 2> ls-error.txt
Ao fazer isso, o sistema automaticamente cria o arquivo, se ele não existir, e, se existir, ele é sobrescrito. Mas, e se não quisermos que nosso arquivo seja sobrescrito?
Nesse caso, podemos usar o operador >> para anexar a saída do programa ao final do arquivo. Fazemos isso da seguinte maneira:
ls -l /usr/bin >> ls-output.txt
Ainda não acredita que é tudo arquivo?
Digite tty no seu terminal, esse comando te retornará o arquivo do seu terminal atual que está
associado ao stdin (o stdout e stderr também são associados a esse mesmo arquivo por padrão).
Abra outro terminal e redirecione a saída do date para o endereço do arquivo dado pelo comando tty.
Redirecionando o Standard Input e wildcards
Lembra do cat?, ele, geralmente, é usado para mostrar o
conteúdo de pequenos arquivos de texto. Mas, como ele aceita mais de um arquivo como argumento, ele também
é usado para juntar o conteúdo de diversos arquivos. Imagine, agora, que você anda escrevendo um livro
em que o conteúdo dele é separado em diversos arquivos. Por exemplo:
capitulo.1.1
capitulo.1.2
capitulo.2.2
⋮
capitulo.15.3
Você pode juntar o conteúdo de todos os arquivos, numa versão completa do livro assim:
cat capitulo* > meulivro.pdf
Assim como o >, esse asterisco (*) é interpretado e expandido pelo shell, e, informalmente, é como se você dissesse para ele: “‘cateie’ [do comando ‘cat’] tudo que começa com ‘capitulo’ e mande isso pro ‘meulivro.pdf’”. O asterisco é o
que chamamos de “wildcard” (ou “carta coringa”), e você pode usá-lo em qualquer parte da sua entrada se quiser e
pode usar mais de um, por exemplo:
ls Do*n*
(Se você tiver a pasta Downloads e Documentos no seu computador, o ls vai listar as duas)
Tá, mas o que isso tem a ver com o redirecionamento do stdin?
E se você tentar o cat sem argumentos? A princípio parece que nada acontece, mas ele está fazendo
exatamente o que deve fazer.
Se você usar o cat sem argumentos, ele lê do stdin, visto que o stdin é associado por padrão ao seu
teclado, ele está esperando a gente digitar alguma coisa! Adicione algum texto e pressione <Enter>.
[user@hostname ~]$ cat
O sábia não sabia que o sábio sabia que o sabiá não sabia assobiar ⏎
O sábia não sabia que o sábio sabia que o sabiá não sabia assobiar
Agora, tecle <Ctrl-d> (segure a tecla Ctrl e aperte “d”) para dizer ao cat que você chegou no
fim do arquivo (End Of File - EOF) no standard input. Como o standard output também é o
terminal pro padrão, o cat apenas copia os o stdin para o stdout. Podemos usar esse comportamento
para escrever num arquivo, por exemplo:
[user@hostname ~]$ cat > sabiá.txt
O sábia não sabia que o sábio sabia que o sabiá não sabia assobiar ⏎
(Não esqueça do <Ctrl-d>!)
Exercício!
Qual a diferença entre cat sabiá.txt e cat < sabiá.txt?
Combinando comandos
Combinando comandos com o redirecionamento de arquivos
Agora, com a noção de redirecionamento de streams, é possível juntar as nossas ferramentas e realizar tarefas que antes talvez fossem impensáveis.
Por exemplo, digamos que você quer ser capaz de listar e ver todos os arquivos de um diretório que tem
muitos arquivos e sub-diretórios com tranquilidade, por exemplo, o /usr/lib:
[user@hostname ~]$ ls -la /usr/lib
Se sua tela não tiver muitos quilômetros de comprimento, provavelmente você não vai ser capaz de visualizar
tudo dentro do frame dela. Então, que tal você redirecionar essa saída para um arquivo e lê-lo com
o less?
[user@hostname ~]$ ls -la /usr/lib > temp
[user@hostname ~]$ less temp
Legal, não é? Vamos ficar criativos! Que tal você tentar listar todos os arquivos comuns que tem apenas
permissão de leitura e escrita no /usr/lib?
— Spoiler Alert —
Primeiro vamos listar todos os arquivos do diretório e redirecionar para um arquivo qualquer:
[user@hostname ~]$ ls -la /usr/lib > temp
Podemos utilizar o próprio temp, também, mas o próximo passo agora é procurar a expressão que a gente
quer, usando o grep:
[user@hostname ~]$ grep 'rw-' temp > grep-out.txt
E aí, conseguimos ler tranquilamente esses arquivos com:
[user@hostname ~]$ less grep-out.txt
Legal!!!
Agora, cada vez mais, estamos pegando o jeito da coisa e, finalmente, combinando nossas ferramentas para alcançar exatamente o que queremos. Entretanto… espero que você se incomode com o fato de estarmos criando vários arquivos temporários para realizar tarefas relativamente simples. Além disso, perceba a quantidade de passos que realizamos pra fazer isso.
Pensando nisso, os criadores do Unix levaram em conta esse sofrimento e criaram o operador que chamamos
de pipe |, que serve justamente para mitigar isso.
Combinando comandos usando pipelines
A ideia de pipe (cano, em Português), é tão literal quanto parece, ele serve para conectar a saída de um comando como a entrada de outro, exatamente como um cano, uma vez conectados, chamamos o resultado de pipeline, que não tem tradução literal para o português, mas seria algo como uma “estação de canos”.
Na prática, isso seria:
[user@hostname ~]$ ls -la /usr/lib | grep 'rw-' | less
Pronto! Os 500 passos que precisávamos fazer usando arquivos temporários, agora não são mais necessários. Uma coisa interessante sobre essa operação é que, na verdade, os comandos são executados ao mesmo tempo e a sincronização entre eles fica por conta do kernel.
É claro que, agora, o céu é o limite, e podemos experimentar um bocado:
[user@hostname ~]$ ls -l | tail -n1
[user@hostname ~]$ ls -l | head | tail
[user@hostname ~]$ ls -l | grep Downloads
Mas, e se eu quiser combinar comandos que não são tão confiáveis assim? Note que o ls, tail, head
e grep raramente vão encontrar problemas. Entretanto, imagine-se na seguinte situação: Você quer
compactar um arquivo gigantesco (suponha que você sabe o comando para isso), e, se houver sucesso na
compactação, você quer deletar o arquivo original e mandar um email (supondo que você tem o mail instalado) para o seu chefe em conjunto com esse arquivo compactado. Como você faria isso com
apenas uma linha de comando e sem precisar se preocupar sentado na frente do computador esperando cada
comando terminar?
Exercícios
Orientações sobre os exercícios
Envie os exercícios de cada dia separados para o email linuxgitpetcc@gmail.com com o assunto sempre sendo: Dia (dia de aula) - (Nome do aluno)
Exercício 0
-
Crie o diretório
/tmp/petcc. -
Dentro desse diretório, crie a pasta
exercícios.
Para cada exercício, a partir desse, crie uma pasta para tal com o nome que preferir, mas que seja ordenado em ordem léxicográfica. Exemplo:
ex001
ex002
⋮
Dentro dos diretórios, crie os arquivos necessários.
Exercício 1
- Crie um diretório com o nome que preferir e, dentro desse diretório, crie três arquivos e três pastas com quaisquer nomes contendo números. Em seguida, coloque o arquivo com menor número dentro da pasta com menor número e assim em diante.
- Escreva a sequência de comandos usada no arquivo
/tmp/petcc/ex002/answer.sh.
Exercício 2
- Crie um diretório chamado
mydir. - Dentro desse diretório, crie um arquivo chamado
mytext.txt. - Use o comando
echopara adicionar a frase “Hello, World!” ao arquivomytext.txt. - Use o comando
catpara exibir o conteúdo do arquiomytext.txt. - Use o comando
cppara copiar o arquivomytext.txtpara um novo arquivo chamadomytext_copy.txt. - Use o comando
rmpara remover o arquivomytext.txt. - Verifique se o arquivo
mytext.txtfoi removido usando o comandols. - Escreva a sequência de comandos usada no arquivo
/tmp/petcc/ex002/resposta.sh.
Exercício 3
- Baixe o arquivo “me_execute.sh”
-
Tente executá-lo usando “./me_execute.sh”
-
Apareceu um erro? Tente resolver o problema investigando o comando
chmodcom uso doman - Execute novamente o arquivo e veja a saída gerada!
Exercício 4
- Crie o diretório
/tmp/petcc/ - Copie os arquivos de todos os exercícios para o um diretório dentro de
/tmp/petcc/ex004. - Tente deletar o diretório que você criou com
rmdir. - Por que não deu certo? Investigue o manual (
man) e descubra a resposta.Dica: dê uma olhada no comando
rm. - Use o
echopara redirecionar a resposta para o arquivo de texto chamado/tmp/petcc/ex004/resposta.sh. - Delete o diretório que você criou inicialmente.
Exercício 5
- No diretório
/tmp/petcc, crie um arquivo chamadosys_info.sh. - Adicione o seguinte conteúdo ao arquivo
sys_info.sh, uma linha de cada vez:
#!/bin/bash
echo "Informações do Sistema:"
uname -a
df -h
free -m
- Use chmod para tornar o arquivo sistema_info.sh executável.
- Execute o comando novamente digitando
./sys_info.she pressione Enter. - Pesquise sobre os comandos
uname,dfefreeutilizando o programaman. - Adicione um comentário explicativo para cada comando no arquivo
resposta.txtpara descrever o que cada um faz. - Execute o script novamente para verificar se tudo está funcionando conforme esperado.
© PET-CC/UFRN 2024 Licenciado sob CC BY-NC-SA.